A Step-by-Step Guide to Using Velero on AWS EKS Clusters via Pulumi
Disaster Recovery, Data Migration made easy!

E
Cloud Native Pilgrim | Kubernetes Enthusiast | Serverless Believer | Customer Experience Architect @ Pulumi | (he/him) | CK{A,AD} |
Search for a command to run...
Disaster Recovery, Data Migration made easy!
Cloud Native Pilgrim | Kubernetes Enthusiast | Serverless Believer | Customer Experience Architect @ Pulumi | (he/him) | CK{A,AD} |
No comments yet. Be the first to comment.
GPU scheduling in Kubernetes has always felt like buying a mansion when you need a studio apartment. A small inference workload that needs 2GB of GPU memory gets scheduled on an entire 80GB A100, and there's nothing you can do about it. The device pl...

TL;DR: The code https://github.com/dirien/quick-bites Nothing is more controversial in the Kubernetes community than whether to use Helm or Kustomize. I always advocate the philosophy of using the right tool for the right job. It avoids the problem...

TL;DR Le code https://github.com/dirien/quick-bites Introduction This article is part three of my series on secret management on Kubernetes with the help of Pulumi. In my first article, we talked about the Sealed Secrets controller. The second arti...

With AWS Lambda

My motivation to write this article comes from the recent blog post of Lily Cohen who had a severe data loss on her Kubernetes cluster.
During a routine GitOps cleanup, YAML manifests responsible for creating Kubernetes namespaces were moved to a directory not tracked by ArgoCD, leading to unintentional data deletion. Although backups were taken using Velero every six hours, the Persistent Volume Claim (PVC) data was not included due to a missing Restic flag, rendering the backups incomplete and the data irretrievable.
Let's have a look at Velero and Pulumi to back up and restore an EKS cluster including the persistent volumes.
Velero is an open-source tool to backup and restore, perform disaster recovery, and migrate Kubernetes cluster resources and persistent volumes.
Velero gives us the following benefits:
Disaster Recovery: Reduces time to recovery in case of infrastructure loss, data corruption, and/or service outages
Data Migration: Enables cluster portability by easily migrating Kubernetes resources from one cluster to another and integrates with DevOps workflows to create ephemeral clones of Kubernetes namespaces
Ephemeral Clusters: Provides a reliable tool to unlock new approaches to cluster lifecycle management treating clusters as "cattle"
Managed Kubernetes services like EKS, AKS, GKE, etc. are great as they take away the burden of managing the control plane. The etcd key-value store is managed by the cloud provider and therefore only accessible through the Kubernetes API Server. Here comes Velero into play.
Velero retrieves etcd data via the Kubernetes API Server, offering significant flexibility in backup options. You can filter which resources to back up based on criteria like namespace or label, and even choose to exclude certain resources from the backup.
Velero manages backup and restore tasks using Custom Resources (CRs) within the Kubernetes cluster. The Velero controller monitors these CRs to execute backup and restore procedures.
This Kubernetes-native methodology offers excellent opportunities to harness the broader Kubernetes ecosystem, including GitOps for delivery or admission controllers for implementing policy-as-code to avoid misconfigurations. Additionally, Velero's CLI can be integrated into existing CI/CD systems, allowing pipelines to trigger backup and restore actions on demand.
Velero has two main components:
A server that runs in your Kubernetes cluster
A command-line client that runs locally
With the command-line client, we can create backups and restore them by creating CRs in the Kubernetes cluster.
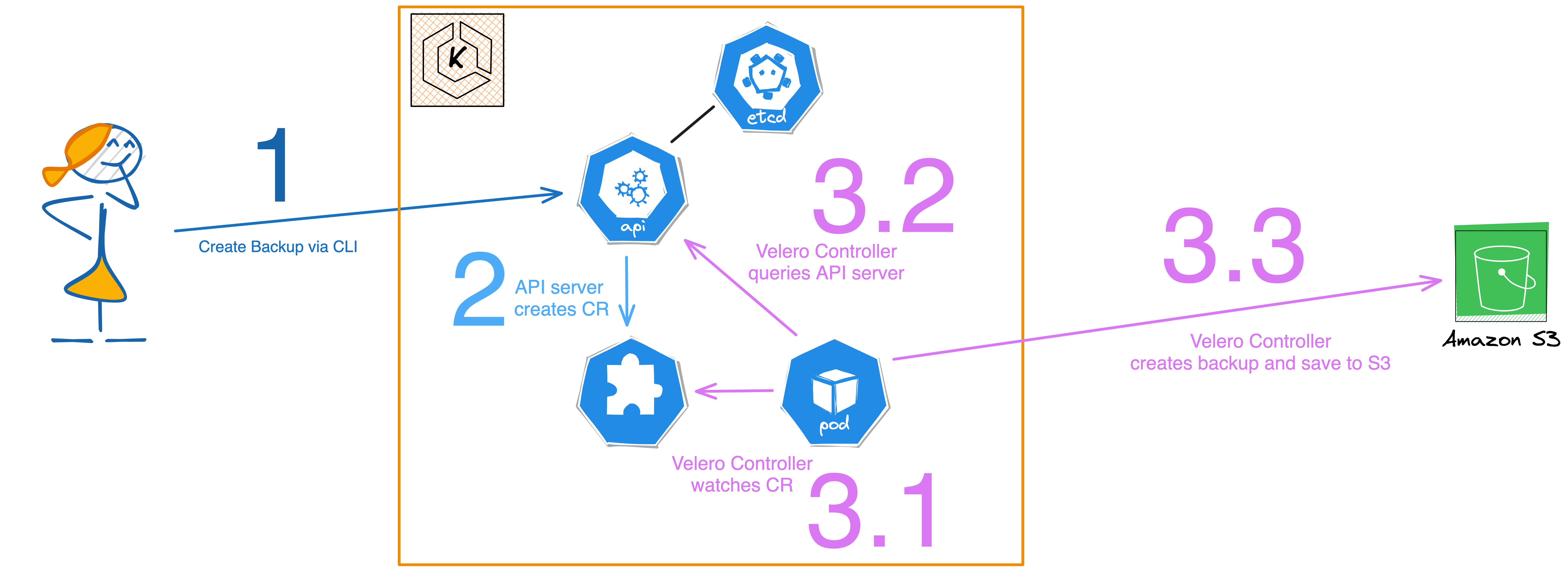
The user initiates a call to the Kubernetes API server using the Velero CLI.
The API server generates a Custom Resource (CR) of kind backups.velero.io.
The Velero Controller then takes the following steps:
Verifies the presence of the CR objects.
Requests the relevant resources from the API server.
Compresses these resources and stores them in an S3 bucket.
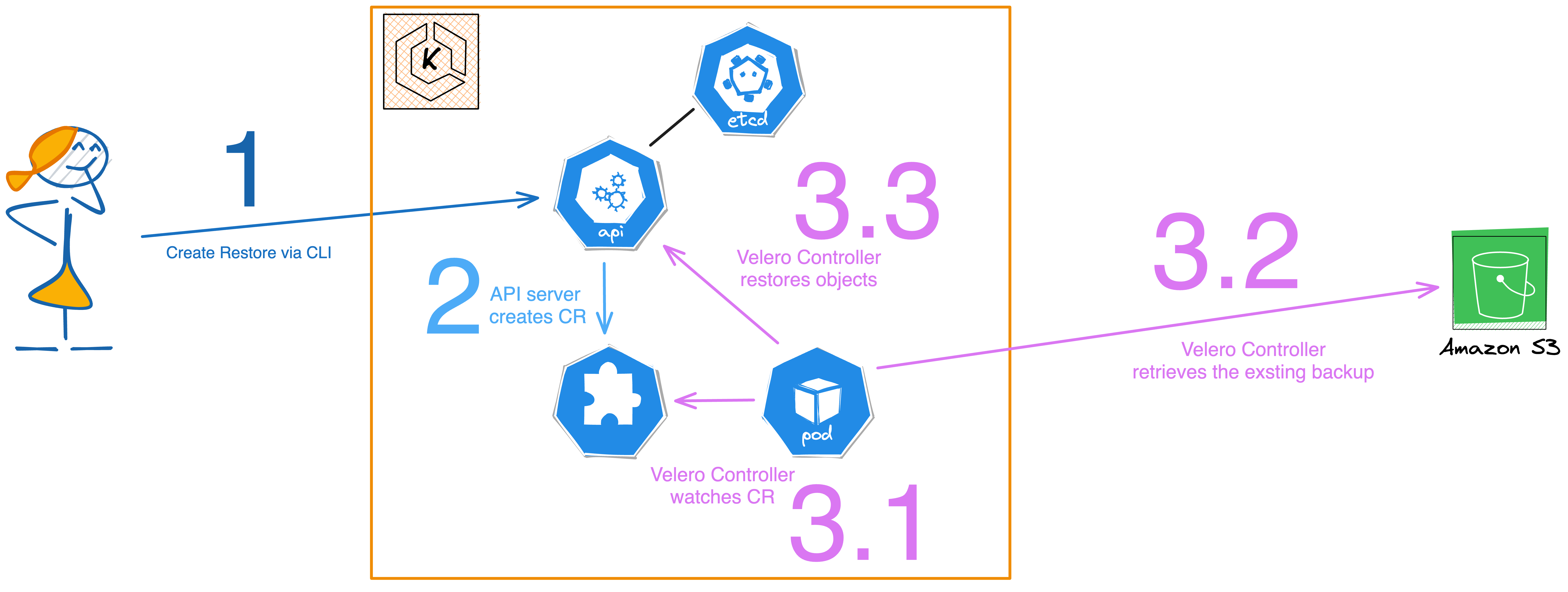
The user initiates a restore request to the Kubernetes API server via the Velero CLI.
In response, the API server creates a Custom Resource (CR) for the restore operation, of kind restores.velero.io.
The Velero Controller then performs the following actions:
Checks for the existence of the specified Restore CR objects.
Fetches the corresponding compressed resources from the S3 bucket.
Decompress these resources and calls the API server to restore them into the Kubernetes cluster.
Having covered the theoretical aspects of Velero, let's now dive into the practical portion of this blog article.
Pulumi Account - this is optional but convenient for handling the state of stack.
kubectl - Required to interact with the Kubernetes cluster. You can install it by following the instructions here.
I will use Golang as my programming language of choice. You can use of course any other language supported by Pulumi.
To create a Pulumi project, run the following commands:
mkdir pulumi-eks-velero
cd pulumi-eks-velero
pulumi new go --force
I am using the
--forceflag as I already created the directory beforehand.
To deploy an EKS cluster, we will use the Pulumi EKS package. The package is available on the Pulumi Registry and is called pulumi-eks.
I am not going into much detail here on how to deploy an EKS cluster with Pulumi. Check the demo code for more details. The only thing I want to mention is that we need to activate the OpenID Connect (OIDC) provider for the cluster and install the AWS EBS CSI driver to support the dynamic provisioning of EBS volumes.
You can do this by setting the CreateOidcProvider flag to true when creating the cluster. We need this as we're going to use IRSA (IAM Roles for Service Accounts) to grant Velero access to the S3 bucket.
The EBS CSI driver installation consists of several steps:
Create the IAM assume role for the EBS CSI driver
Create the EBS IAM policy
Deploy the EBS CSI driver via Helm
Here is the code for the EBS CSI driver installation:
package main
// omitted code for brevity
func main() {
pulumi.Run(func(ctx *pulumi.Context) error {
// omitted code for brevity
ebsRole, err := iam.NewRole(ctx, "velero-ebs-role", &iam.RoleArgs{
AssumeRolePolicy: pulumi.All(cluster.Core.OidcProvider().Arn(), cluster.Core.OidcProvider().Url()).ApplyT(func(args []interface{}) string {
arn := args[0].(string)
url := args[1].(string)
assumeRolePolicy, _ := iam.GetPolicyDocument(ctx, &iam.GetPolicyDocumentArgs{
Statements: []iam.GetPolicyDocumentStatement{
{
Effect: pulumi.StringRef("Allow"),
Actions: []string{
"sts:AssumeRoleWithWebIdentity",
},
Principals: []iam.GetPolicyDocumentStatementPrincipal{
{
Type: "Federated",
Identifiers: []string{
arn,
},
},
},
Conditions: []iam.GetPolicyDocumentStatementCondition{
{
Test: "StringEquals",
Values: []string{
ebsServiceAccount,
},
Variable: fmt.Sprintf("%s:sub", url),
},
},
},
},
})
return assumeRolePolicy.Json
}).(pulumi.StringOutput),
})
if err != nil {
return err
}
ebsPolicyFile, _ := os.ReadFile("./policies/ebs-iam-policy.json")
ebsIAMPolicy, err := iam.NewPolicy(ctx, "velero-ebs-policy", &iam.PolicyArgs{
Policy: pulumi.String(ebsPolicyFile),
}, pulumi.DependsOn([]pulumi.Resource{ebsRole}))
if err != nil {
return err
}
ebsRolePolicyAttachment, err := iam.NewRolePolicyAttachment(ctx, "velero-esb-role-attachment", &iam.RolePolicyAttachmentArgs{
PolicyArn: ebsIAMPolicy.Arn,
Role: ebsRole.Name,
}, pulumi.DependsOn([]pulumi.Resource{ebsIAMPolicy}))
if err != nil {
return err
}
_, err = helm.NewRelease(ctx, "aws-ebs-csi-driver", &helm.ReleaseArgs{
Chart: pulumi.String("aws-ebs-csi-driver"),
Version: pulumi.String("2.22.0"),
Namespace: pulumi.String("kube-system"),
ForceUpdate: pulumi.Bool(true),
RepositoryOpts: helm.RepositoryOptsArgs{
Repo: pulumi.String("https://kubernetes-sigs.github.io/aws-ebs-csi-driver"),
},
Values: pulumi.Map{
"controller": pulumi.Map{
"serviceAccount": pulumi.Map{
"annotations": pulumi.Map{
"eks.amazonaws.com/role-arn": ebsRole.Arn,
},
},
},
"storageClasses": pulumi.Array{
pulumi.Map{
"name": pulumi.String("ebs-sc"),
"volumeBindingMode": pulumi.String("WaitForFirstConsumer"),
},
},
"volumeSnapshotClasses": pulumi.Array{
pulumi.Map{
"name": pulumi.String("ebs-vsc"),
"deletionPolicy": pulumi.String("Delete"),
},
},
},
}, pulumi.Provider(provider), pulumi.DependsOn([]pulumi.Resource{ebsRolePolicyAttachment}))
if err != nil {
return err
}
return nil
})
}
Important to note here that we create the service account for the EBS CSI driver with the eks.amazonaws.com/role-arn annotation. This annotation is required by the EBS CSI driver to assume the IAM role we created before. Additionally, we create the storage class and volume snapshot class for the EBS CSI driver as well. You can decide if you want to keep this or deploy the storage class and volume snapshot class as separate Kubernetes resources.
Next, we need to create the S3 bucket where we will store the backups. We will use the Pulumi AWS package to create the S3 bucket and the corresponding bucket public access block.
package main
// omitted code for brevity
func main() {
pulumi.Run(func(ctx *pulumi.Context) error {
// omitted code for brevity
bucket, err := s3.NewBucket(ctx, "velero-bucket", &s3.BucketArgs{
Bucket: pulumi.String("velero-eks-bucket-dirien"),
Tags: pulumi.StringMap{
"Name": pulumi.String("velero-eks-bucket-dirien"),
},
})
if err != nil {
return err
}
_, err = s3.NewBucketPublicAccessBlock(ctx, "velero-bucket-public-access-block", &s3.BucketPublicAccessBlockArgs{
Bucket: bucket.ID(),
BlockPublicAcls: pulumi.Bool(true),
BlockPublicPolicy: pulumi.Bool(true),
IgnorePublicAcls: pulumi.Bool(true),
RestrictPublicBuckets: pulumi.Bool(true),
})
if err != nil {
return err
}
return nil
})
}
One thing to note here is that we set the BlockPublicAcls, BlockPublicPolicy, IgnorePublicAcls, and the RestrictPublicBuckets flags to true. This is a best practice to prevent the S3 bucket from being publicly accessible.
At last, we're ready to deploy Velero. The first step is setting up the IRSA to give Velero the required permissions to access the S3 bucket. This process is similar to installing the EBS CSI driver, albeit with different policies. Once that's done, we'll proceed to deploy Velero using its Helm chart.
package main
// omitted code for brevity
func main() {
pulumi.Run(func(ctx *pulumi.Context) error {
// omitted code for brevity
saRole, err := iam.NewRole(ctx, "velero-sa-role", &iam.RoleArgs{
AssumeRolePolicy: pulumi.All(cluster.Core.OidcProvider().Arn(), cluster.Core.OidcProvider().Url()).ApplyT(func(args []interface{}) string {
arn := args[0].(string)
url := args[1].(string)
assumeRolePolicy, _ := iam.GetPolicyDocument(ctx, &iam.GetPolicyDocumentArgs{
Statements: []iam.GetPolicyDocumentStatement{
{
Actions: []string{
"sts:AssumeRoleWithWebIdentity",
},
Conditions: []iam.GetPolicyDocumentStatementCondition{
{
Test: "StringEquals",
Values: []string{
veleroServiceAccount,
},
Variable: fmt.Sprintf("%s:sub", url),
},
},
Principals: []iam.GetPolicyDocumentStatementPrincipal{
{
Type: "Federated",
Identifiers: []string{
arn,
},
},
},
Effect: pulumi.StringRef("Allow"),
},
},
})
return assumeRolePolicy.Json
}).(pulumi.StringOutput),
})
if err != nil {
return err
}
veleroIAMPolicy, err := iam.NewPolicy(ctx, "velero-iam-policy", &iam.PolicyArgs{
Policy: pulumi.All(bucket.Bucket).ApplyT(func(args []interface{}) string {
name := args[0].(string)
veleroIAMPolicy, _ := iam.GetPolicyDocument(ctx, &iam.GetPolicyDocumentArgs{
Statements: []iam.GetPolicyDocumentStatement{
{
Effect: pulumi.StringRef("Allow"),
Actions: []string{
"ec2:DescribeVolumes",
"ec2:DescribeSnapshots",
"ec2:CreateTags",
"ec2:CreateVolume",
"ec2:CreateSnapshot",
"ec2:DeleteSnapshot",
},
Resources: []string{
"*",
},
},
{
Effect: pulumi.StringRef("Allow"),
Actions: []string{
"s3:GetObject",
"s3:DeleteObject",
"s3:PutObject",
"s3:AbortMultipartUpload",
"s3:ListMultipartUploadParts",
},
Resources: []string{
fmt.Sprintf("arn:aws:s3:::%s/*", name),
},
},
{
Effect: pulumi.StringRef("Allow"),
Actions: []string{
"s3:ListBucket",
},
Resources: []string{
fmt.Sprintf("arn:aws:s3:::%s", name),
},
},
},
})
return veleroIAMPolicy.Json
}).(pulumi.StringOutput),
})
if err != nil {
return err
}
_, err = iam.NewRolePolicyAttachment(ctx, "velero-iam-role-attachment", &iam.RolePolicyAttachmentArgs{
PolicyArn: veleroIAMPolicy.Arn,
Role: saRole.Name,
})
_, err = helm.NewRelease(ctx, "velero", &helm.ReleaseArgs{
Chart: pulumi.String("velero"),
Version: pulumi.String("5.0.2"),
RepositoryOpts: helm.RepositoryOptsArgs{
Repo: pulumi.String("https://vmware-tanzu.github.io/helm-charts"),
},
Namespace: pulumi.String(veleroNamespace),
CreateNamespace: pulumi.Bool(true),
Values: pulumi.Map{
"serviceAccount": pulumi.Map{
"server": pulumi.Map{
"name": pulumi.String("velero"),
"annotations": pulumi.StringMap{
"eks.amazonaws.com/role-arn": saRole.Arn,
},
},
},
"credentials": pulumi.Map{
"useSecret": pulumi.Bool(false),
},
"podSecurityContext": pulumi.Map{
"fsGroup": pulumi.Int(65534),
},
"initContainers": pulumi.Array{
pulumi.Map{
"name": pulumi.String("velero-plugin-for-aws"),
"image": pulumi.String("velero/velero-plugin-for-aws:v1.7.1"),
"imagePullPolicy": pulumi.String("IfNotPresent"),
"volumeMounts": pulumi.Array{
pulumi.Map{
"name": pulumi.String("plugins"),
"mountPath": pulumi.String("/target"),
},
},
},
},
"configuration": pulumi.Map{
"backupStorageLocation": pulumi.Array{
pulumi.Map{
"name": pulumi.String("velero-k8s"),
"provider": pulumi.String("aws"),
"bucket": bucket.Bucket,
"prefix": pulumi.String("velero"),
"config": pulumi.Map{
"region": pulumi.String("eu-central-1"),
},
"default": pulumi.Bool(true),
},
},
"volumeSnapshotLocation": pulumi.Array{
pulumi.Map{
"name": pulumi.String("velero-k8s-snapshots"),
"provider": pulumi.String("aws"),
"config": pulumi.Map{
"region": pulumi.String("eu-central-1"),
},
},
},
},
},
}, pulumi.Provider(provider))
if err != nil {
return err
}
return nil
})
}
Similar to the EBS CSI driver setup, we first create a service account for Velero, annotating it with eks.amazonaws.com/role-arn. Thanks to the IRS approach, there's no need to create a separate AWS secret; you can simply set credentials.useSecret to false in the Helm chart values.
To enable backup and restore functionalities for EBS volumes, it's crucial to install the AWS plugin for Velero. This can be achieved using initContainers in the Helm chart.
The final step involves establishing the backup storage location and the volume snapshot location. We will use the previously created S3 bucket for storing backups and set the default AWS volume snapshot location, all of which can be configured in the Helm chart values (configurations).
Now we can deploy the stack. Run the following commands to deploy the stack:
pulumi up
Make sure you have the AWS CLI configured with the correct credentials and region before you run the command.
With the stack now deployed, it's time to test the backup and restore functionalities. Ensure that you have the Velero CLI installed, as we'll be using it to execute the backup and restore processes.
Before proceeding with creating a backup, you'll first need to set up a namespace and a simple pod that includes a persistent volume claim (PVC).
apiVersion: v1
kind: Namespace
metadata:
name: velero-test
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: ebs-claim
namespace: velero-test
spec:
accessModes:
- ReadWriteOnce
storageClassName: ebs-sc
resources:
requests:
storage: 1Gi
---
apiVersion: v1
kind: Pod
metadata:
name: app
namespace: velero-test
spec:
containers:
- name: app
image: centos
command: ["/bin/sh"]
args: ["-c", "while true; do sleep 5; done"]
volumeMounts:
- name: persistent-storage
mountPath: /data
volumes:
- name: persistent-storage
persistentVolumeClaim:
claimName: ebs-claim
Save the code above in a file called test.yaml and run the following command to create the Pod. You need to get the kubeconfig for the cluster first using the following command:
pulumi stack output kubeconfig --show-secrets > kubeconfig.yaml
Now you can create the pod using the following command:
kubectl --kubeconfig=kubeconfig.yaml apply -f test.yaml
This will create a Pod in the velero-test namespace with a persistent volume claim. To create some data in the volume, we can exec into the Pod and create a file in the volume:
kubectl exec -it app -n velero-test -- sh -c 'echo "Hi, today is $(date)" > /data/test.txt'
Check if the file is created:
kubectl exec -it app -n velero-test -- sh -c 'cat /data/test.txt'
You should see the following output:
Hi, today is Tue Sep 5 09:21:53 UTC 2023
This should be enough to simulate to show the backup and restore functionality of Velero.
To create a backup, we need to create a backup CR in the Kubernetes cluster. We can do this by running the following command:
velero backup create velero-test-backup --include-namespaces velero-test --wait
This will create a backup of the velero-test namespace and wait until the backup is completed.
Backup request "velero-test-backup" submitted successfully.
Waiting for backup to complete. You may safely press ctrl-c to stop waiting - your backup will continue in the background.
..
Backup completed with status: Completed. You may check for more information using the commands `velero backup describe velero-test-backup` and `velero backup logs velero-test-backup`.
To display details about the backup, run the following command with the --details flag.
velero backup describe velero-test-backup --details
You should see similar output like this.
Name: velero-test-backup
Namespace: velero
Labels: velero.io/storage-location=velero-k8s
Annotations: velero.io/source-cluster-k8s-gitversion=v1.27.4-eks-2d98532
velero.io/source-cluster-k8s-major-version=1
velero.io/source-cluster-k8s-minor-version=27+
Phase: Completed
Namespaces:
Included: velero-test
Excluded: <none>
Resources:
Included: *
Excluded: <none>
Cluster-scoped: auto
Label selector: <none>
Storage Location: velero-k8s
Velero-Native Snapshot PVs: auto
TTL: 720h0m0s
CSISnapshotTimeout: 10m0s
ItemOperationTimeout: 1h0m0s
Hooks: <none>
Backup Format Version: 1.1.0
Started: 2023-09-03 15:45:28 +0200 CEST
Completed: 2023-09-03 15:45:30 +0200 CEST
Expiration: 2023-10-03 15:45:28 +0200 CEST
Total items to be backed up: 6
Items backed up: 6
Resource List:
v1/ConfigMap:
- velero-test/kube-root-ca.crt
v1/Namespace:
- velero-test
v1/PersistentVolume:
- pvc-1395e1fd-eae6-4bb2-922a-e5dd5839a696
v1/PersistentVolumeClaim:
- velero-test/ebs-claim
v1/Pod:
- velero-test/app
v1/ServiceAccount:
- velero-test/default
Velero-Native Snapshots:
pvc-1395e1fd-eae6-4bb2-922a-e5dd5839a696:
Snapshot ID: snap-0595966a00a41783b
Type: gp3
Availability Zone: eu-central-1b
IOPS: <N/A>
Navigate to the AWS console and inspect the S3 bucket. Inside, you'll likely find a folder named velero containing the backup files.
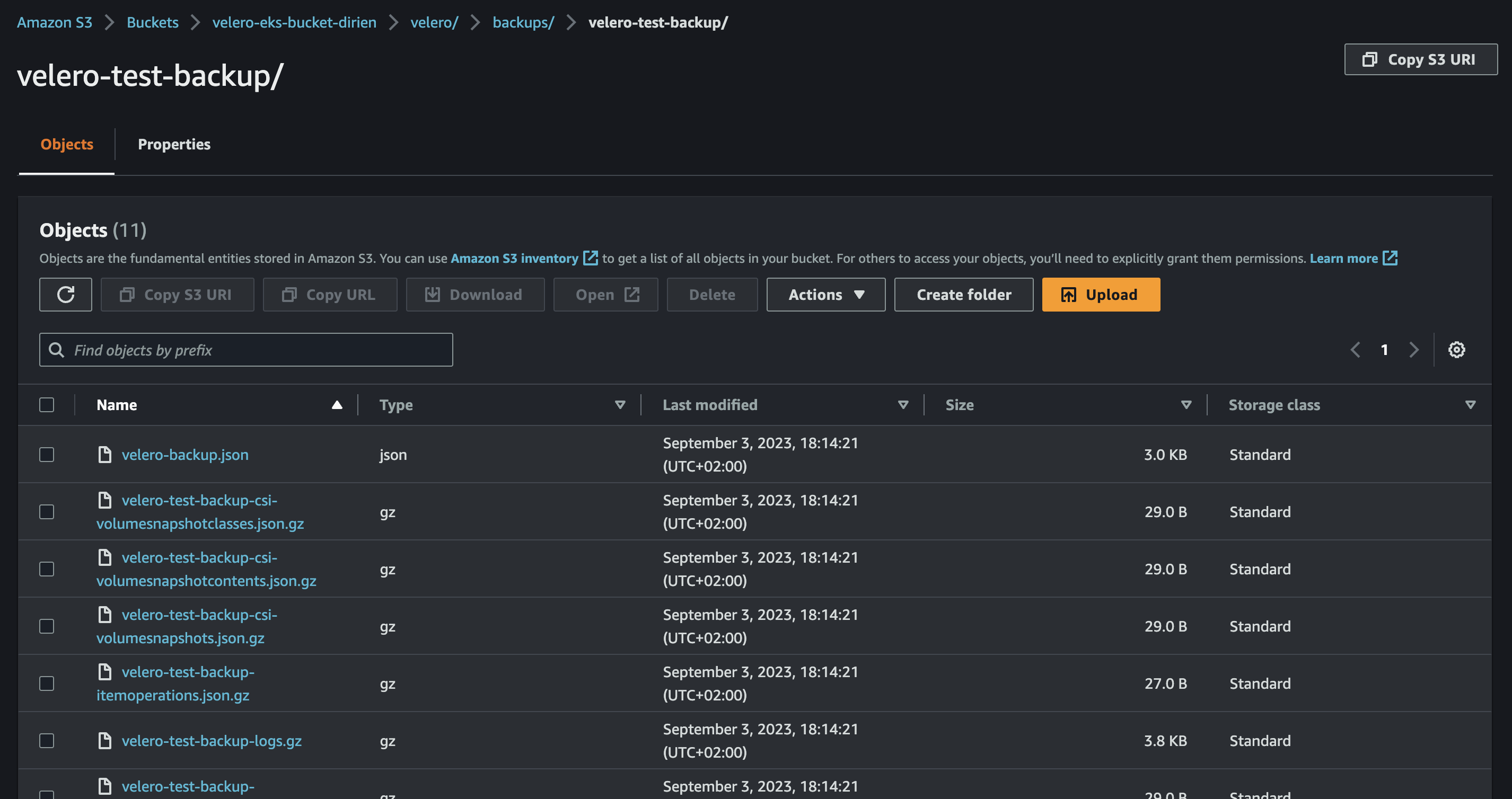
To simulate a data loss, we can simply delete the velero-test namespace:
kubectl delete ns velero-test
Check if the namespace is deleted:
kubectl get ns
Oh no, the namespace is gone. We need to restore it from the backup. Urgently! Production is down!
To restore the backup, we need to create a restore CR in the Kubernetes cluster. We can do this by running the following command:
velero restore create velero-test-restored --from-backup velero-test-backup --wait
This will restore the backup and wait until the restore is completed.
Restore request "velero-test-restored" submitted successfully.
Waiting for restore to complete. You may safely press ctrl-c to stop waiting - your restore will continue in the background.
.
Restore completed with status: Completed. You may check for more information using the commands `velero restore describe velero-test-restored` and `velero restore logs velero-test-restored`.
We can also check the details of the restore similar to the backup:
velero restore describe velero-test-restored --details
velero restore describe velero-test-restored --details
Name: velero-test-restored
Namespace: velero
Labels: <none>
Annotations: <none>
Phase: Completed
Total items to be restored: 6
Items restored: 6
Started: 2023-09-03 18:18:26 +0200 CEST
Completed: 2023-09-03 18:18:27 +0200 CEST
... omitted for brevity
Now we can check if the everything is restored, including the data in the volume:
kubectl exec -it app -n velero-test -- sh -c 'cat /data/test.txt'
And yes, the data is back, the timestamp is the same as before:
kubectl exec -it app -n velero-test -- sh -c 'cat /data/test.txt'
Hi, today is Tue Sep 5 09:21:53 UTC 2023
Since the stack is no longer needed, you can proceed to delete it. Execute the following command to remove the stack:
pulumi destroy
This will delete all the resources created by the stack.
In this blog post, we've explored how to deploy Velero using Pulumi and how to carry out backup and restore operations on an EKS cluster with EBS volumes. Velero is a great tool to handle disaster recovery and data migration scenarios.
In further blog posts, I will show some more advanced use cases of Velero including the integration into GitOps engines like ArgoCD or Flux.
Stay tuned for more!